Logseq 是有一次在跟 Randy 聊天时,他提到最近用得比较多的笔记工具。试用了之后,就被吸引了。经过一段时间摸索,找到了比较舒服的使用姿势,跟大家分享下。
PS: Bytetalk 有一期跟 Logseq 创始人的访谈播客,感兴趣的话可以听一下
PPS: Randy 做过一个视频,分享了他使用 Logseq 的一些经验
Logseq 是什么
Logseq 是一个以 Outline 为组织形式,以 Block 为核心,支持双向链接和灵活查询的笔记工具。由于它的强大和灵活,很多人(包括我)都用它来 Organize Life。
相比于其他的笔记工具,Logseq 的独特点有:
- 极低的记录门槛。每天会自动新建 Journal,然后直接写就行了。Outline 模式也让输入变得非常轻量。
- 强大的查询能力。基于 Outline 组织模式的笔记工具,如果欠缺聚合能力,就容易出现孤岛,Logseq 内置了 Simple Query 和 Advanced Query 两种模式,可以很好地按需聚合内容。
- 开源。开源给人一种安心感,也能体现创作者对代码的信心。
- 免费。嗯,这个理由很充分了···
- Local Data。数据存在本地,不用担心数据泄露或者被用来作为大数据的训练集,也能让 App 的体验更流畅(相比 Online Service,如 Roam Research)。
- Markdown。没有使用私有格式,其他工具也能打开/浏览文件内容,也方便对数据做二次开发。
- 活跃的社区。不用担心没人用,导致停止开发,遇到问题也能愉快地交流。
PS: Logseq 的部分投资人也是 Logseq 的重度用户,甚至会写 Logseq 的插件
当然槽点也是有的,比如设计上还不够精细,文档也有待完善,Advanced Query 虽然很好用,但门槛也很高。
以天为单位来录入内容的另一好处是方便回顾,如果想知道哪天做了哪些事,打开当天的页面就能了解大概。
Logseq 使用起来很自由,但如果缺少规范也容易迷失,无法发挥最大威力,下面就来聊聊我的一些使用经验,仅供参考。
一些概念
Block
Block 是 Logseq 中很重要的一个概念,随便在里面输入一段话,这段话就是一个 Block。Block 可以有 Parent 和 Children
// 每一行都是 Block
// 缩进后会成为 Child Block
// 点击左边的小圆点可以进入到 Block 内页
// 也可以折叠和展开
• Logseq 是一个不错的笔记工具
• 开源且免费
• 使用方便
• ...
Page
如果只有 Block,那这些 Block 之间就很难建立关联,Page 可以解决这个问题(Tag 也可以)。只要在一段文字的前后加入两个中括号就行
// Logseq 会自动成为一个 Page,title 就是 Logseq
// 点击进去后还能看到 Back Link,也就是这个 Block
[[Logseq]] 最近的一些更新
Tag
跟 Page 类似,Tag 也可以达到聚合 Block 的效果,只要在前面加上 #。既然两者效果类似,那使用场景有什么区别呢?我的习惯是:如果是一段语句的组成部分就用 Page,其他场景就用 Tag(因为 Tag 无法处理空格,所以我更习惯用 #[[Tag]] 这种形式)。
Logseq 的 advanced query 学起来好累啊 #Thoughts
写一篇 [[关于 Logseq]] 的文章
Back Link
所有有 Tag 或 Page 的 Block 都会被聚合在一起,同时还会带上日期,这个非常方便。
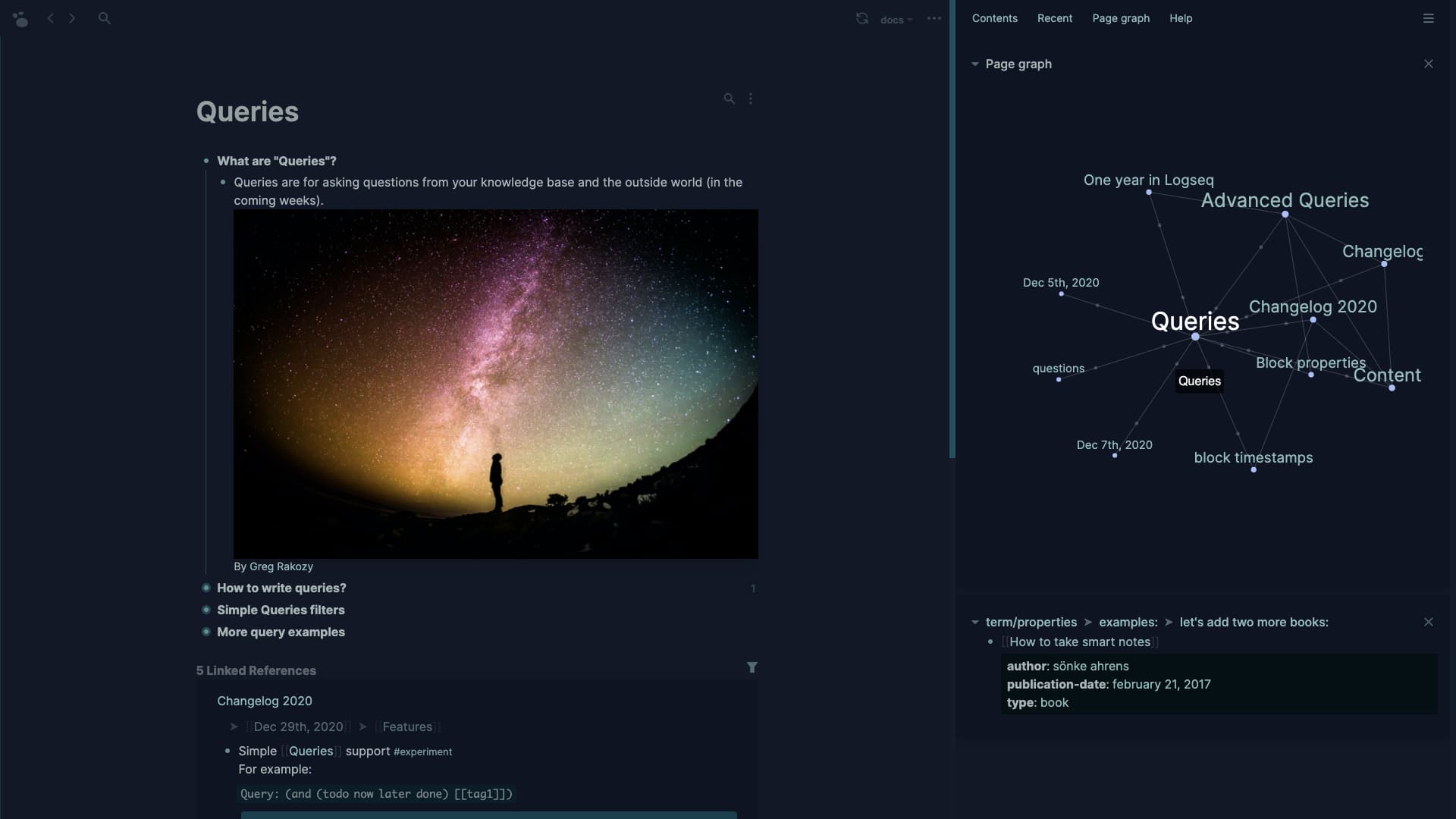
Properties
Page 和 Block 都可以有自己的属性,对于 Page 来说,第一行如果是 XXX::YYY 这样的形式就会被认为是该页面的属性,对于 Block 则是下一个缩进行。

上图中,关于个人笔记这个页面就有一个 is 的属性,该属性的 value 是 [[Blog]]。结合 Advanced Query 可以实现一些很方便的效果。
给页面加属性毕竟是一件有成本的事情,我会对持续多天的页面(通常是一个领域或项目)的内容加上属性,对于像 #Pearls 这些不那么重要的内容就只是加 Tag
Simple Query
Simple Query 比较容易理解,但能力也有限,格式为 ,常用的有:
Advanced Query
Advanced Query 会更复杂,但能力也更强,格式如下:
{:title [:h2 "Your query title"]
:query [:find (pull ?b [*])
:where ...]
:inputs [...]
:view (fn [query-result] [:div ...])
:result-transform (fn [query-result] ...)
:collapsed? true}
使用要点
标签和属性的选择
通常出于便利考虑,会选择给 Block 加标签,以聚合同类内容,比如 [[pnpm 的设计理念]] 这个包含 Page 的 Block,可以加一个 #[[Frontend]] 标签,这样进入到 Frontend 页面后就能看到 [[pnpm 的设计理念]] 这个 Block 了。
那么这两种用法有什么区别呢?
// Tag
[[pnpm 的设计理念]] #[[Programming]] #[[Frontend]]
// Properties
pnpm 的设计理念
category:: [[Programming]]
sub-category:: [[Frontend]]
直接用 Tag 的话,有两个问题:
- 如果
[[pnpm 的设计理念]]下的内容较多,要分很多天来啃,那么这个 Block 都要手动加上#[[Frontend]]这个标签。 - 如果要给这个 Block 加上其他的 Tag,如
#[[Build Tool]],那么就要找到所有引用该页面的 Block,挨个加上这个 Tag。
如果最近一段时间在研究这个话题,那么可以每天 copy ref 过来,然后在下面补充学习内容。学习完后,如果其他 Block 要引用 [[pnpm 的设计理念]],比如 正如在 [[pnpm 的设计理念]] 中所说... 这段话,不加标签,那么这个 Block 就会失去跟 [[Frontend]] [[Programming]] 的关联,如果要加标签则容易遗漏,也显得奇怪。
对于会被其他 Block 引用的 Page,可以采用给页面加属性,然后结合 Advanced Query 来实现。
关于使用 flat blocks(block 之间是平行关系) 还是 nest blocks(block 之间是层级关系),这个因人而异。我之前喜欢用 nest blocks,如:
• [[Thoughts]]
• Logseq 还是挺好用的
• 应该要写一篇使用 Logseq 心得的文章
• ···
这样,可以建立 Daily 模版,然后只要往对应的 Block 下面添加内容就行了。进入页面后,也能看到相关的 Block。但如果 Block 的属性复杂一些,如既属于编程,同时还是一本书,就不知道该放在哪个 Block 下面了。
flat blocks 就像这样:
• 冰椰拿铁什么时候这么难喝了 #Tiny
• 后面两个人说话好大声呀 #Tiny
• 晚上想看一部电影 #Thoughts
后来对 nest blocks 和 flat blocks 定了个规则,只有有明确从属关系的才使用 nest blocks(如书摘,文摘),其他默认用 flat blocks。
页面属性和高级检索
页面属性上面已有介绍(页面的第一行以 Key::Value 这样的格式书写),我常用的属性有:
- is: 表示这个 Page 是什么,如
is::[[Blog]] - category: 这个 Page 的分类,如
category::[[Programming]] - sub-category: 这个 Page 的子分类,如
sub-category::[[Frontend]] - medium: 这个 Page 的媒介类型(视频、书、文章等),如
medium::[[Book]]
一开始没有分这么细,用 tags::[[Book]] [[Programming]] 这种形式聚合在一起。但在写 Query 时遇到了障碍,被迫「降级」成这种写法。
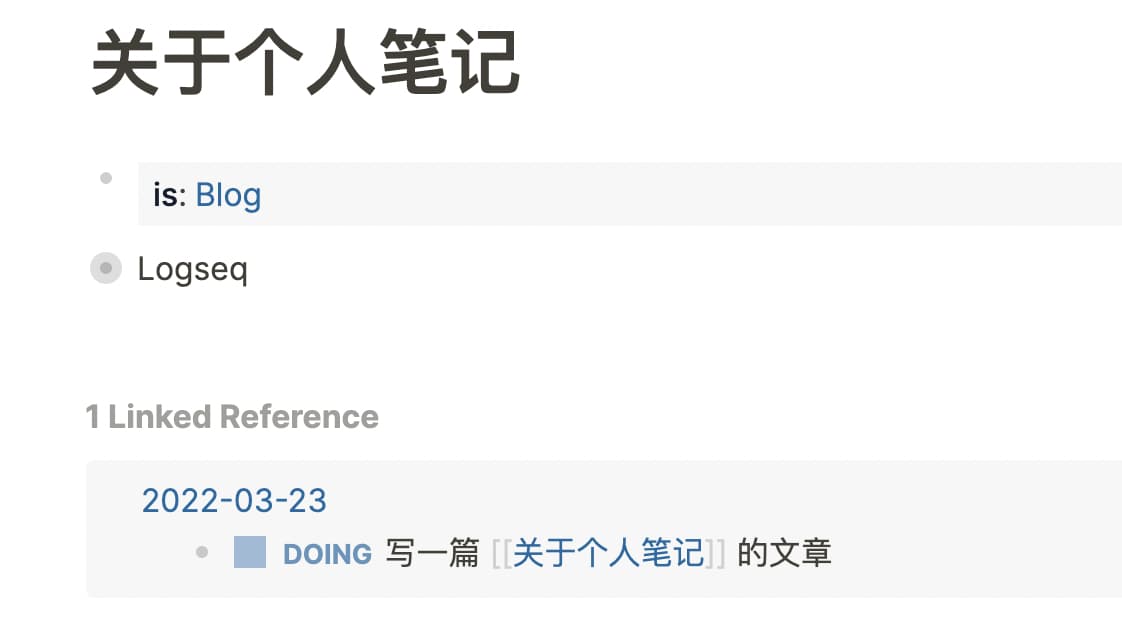
然后就可以用 Query 把这些 Block 找出来了。比如可以找到所有包含 category::[[Programming]] 属性的页面的 Block。如果只是找出页面是不够的,我们来看下对比。
上面是 Block,下面是 Page,通常我们更想要得到上面的效果。为此,需要写 Advanced Query,下面这段代码会找到所有引用了包含 category 属性为 Programming 的页面的 Block。
#+BEGIN_QUERY
; 以下注释是我查找网上文章结合自己的理解,不一定对
; '?xxx' 表示一个变量
; '$' 表示数据库
; ':xxx' 表示字段和查询关键字
{:title [:h2 "Todo"]
:query [:find (pull ?b [*]) ;找到所有符合条件的条目,'*' 表示条目的所有字段
:in $ ?category ;'?category' 就是通过 'inputs' 传过来的变量
:where
[?b :block/ref-pages ?p] ;条件语句用 '[]' 表示,?p 是什么下面会说明
[?p :block/properties ?pr] ;?p 是包含了 properties 为 ?pr 的页面,?pr 是什么,下面会说明
[(get ?pr :category) ?t] ; get 是获取 object 的属性,并将它设置为 ?t
[(contains? ?t ?category)]; contains?(注意'?'在后面)表示 predict,也就是符合特定条件
(not [?b :block/marker ?m]); not [xxx] 表示对 [xxx] 的结果取反
]
:inputs ["Programming"] ; 传入一个参数
}
#+END_QUERY
如果要找到标记为 TODO 的,稍作下调整即可:
#+BEGIN_QUERY
{:title [:h2 "Doing"]
:query [:find (pull ?b [*])
:in $ ?category
:where
[?b :block/marker ?m]
[(= ?m "TODO")]
[?b :block/ref-pages ?p]
[?p :block/properties ?pr]
[(get ?pr :category) ?t]
[(contains? ?t ?category)]
]
:inputs ["Programming"]
}
#+END_QUERY
这里使用 :inputs [:current-page] 会更加灵活,但 Logseq 对 current-page 做了小写处理,导致 (contains? ?t ?category) 无法匹配,换用其他写法如 (some #(= (clojure.string/lower-case %) ?current-page) (into [] ?t)) (将 set 先转为 vect,再通过 some 判断是否有一个 item,小写化之后跟 ?current-page 一样),也不行,所以就手动传入 Page Name 了。
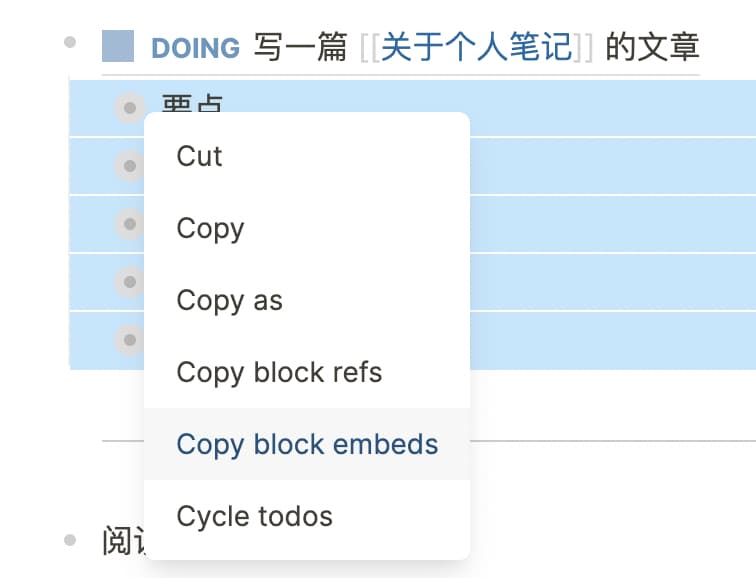
使用 Copy block embed 来聚合内容到页面
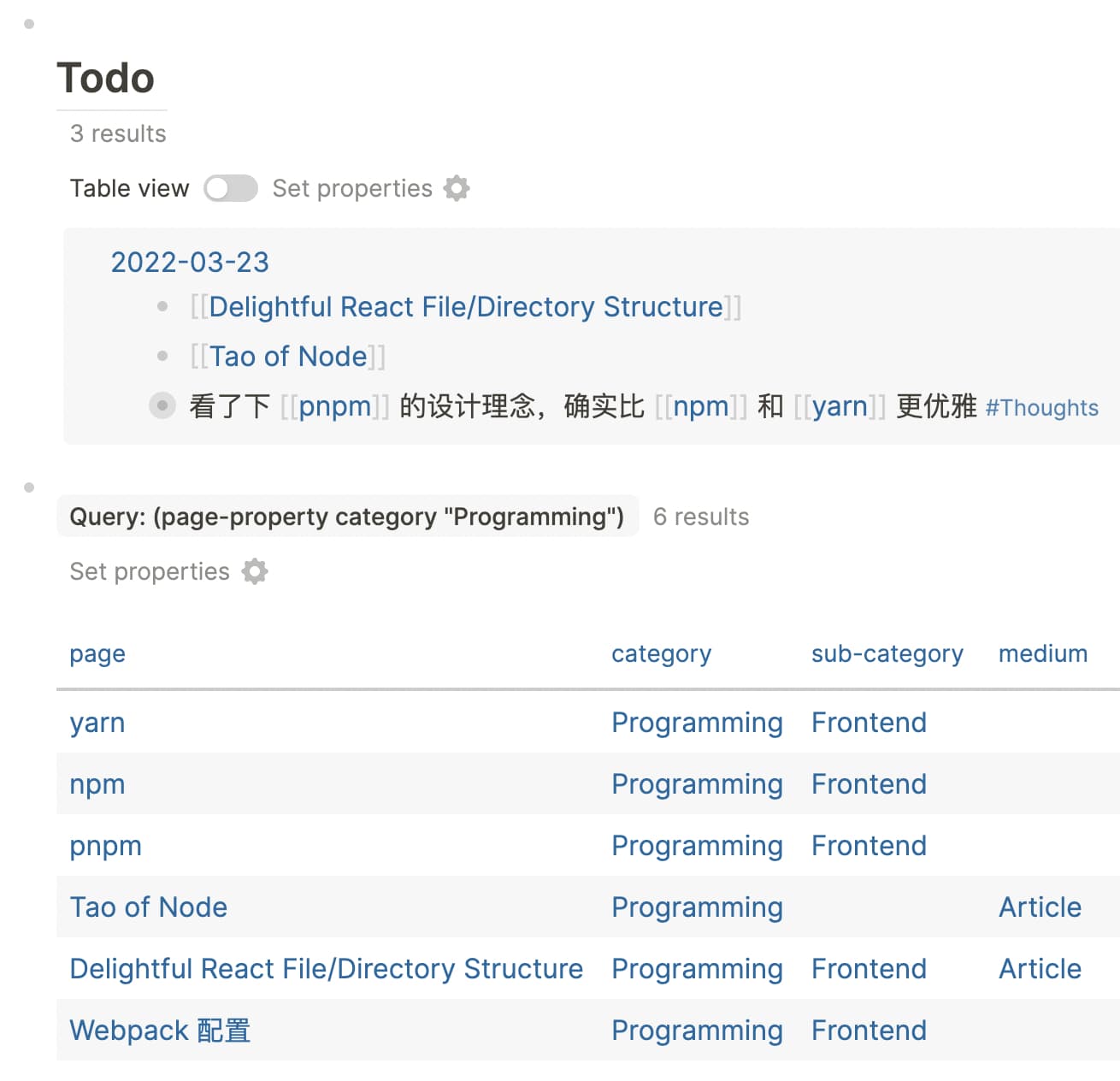
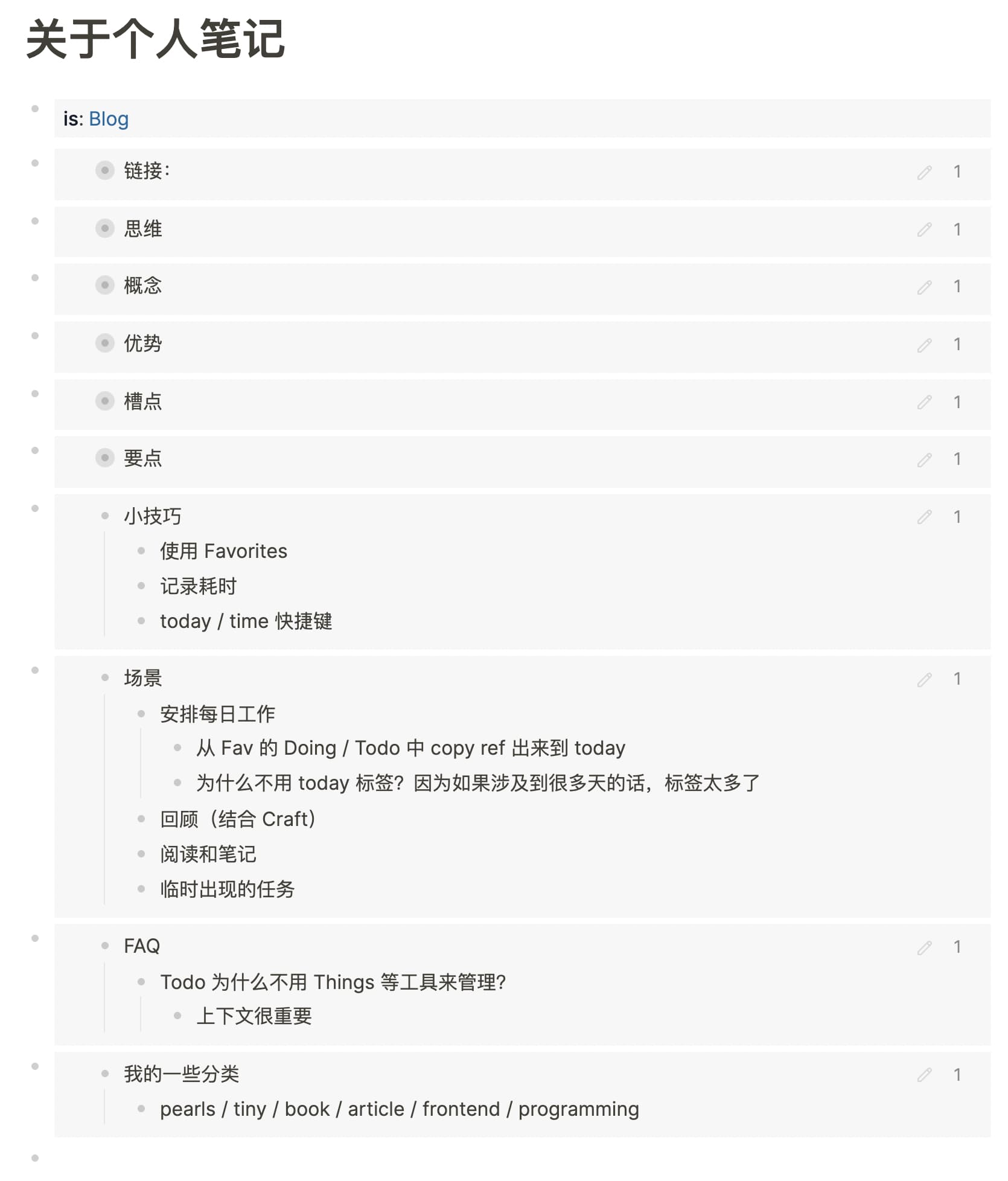
这是某一天的 Journal 页,每天的页面内容大概就是这个样子

可以看到有些 Block 打了标签,有些没有。没打标签的,通常会 Link 到一个 Page,在 Page 里会有相关的属性,通过属性可以将 Block Query 出来。
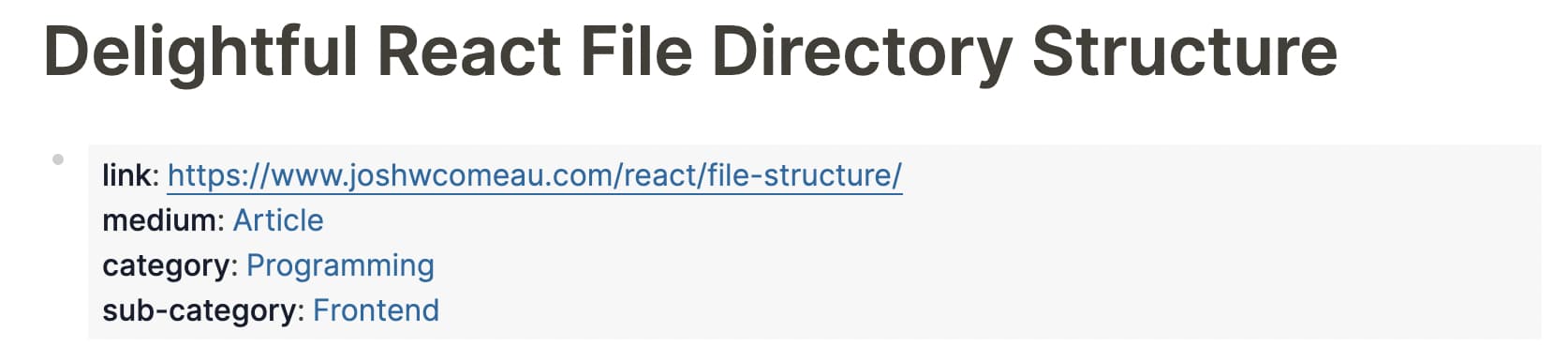
因为这个 Page 有可能在其他 Block 中被引用,所以选择了 Properties
展开的内容就记在 Block 下,这样回顾时也方便知道每天都记了哪些内容。但这样会比较零散,其他 Block 再引用该 Page 时,只能看到内容分散在不同天的 Block 下。这里有一个 Tip 是使用 Copy block embed。将每天记录的内容 Copy block embeds
然后在对应的页面粘贴即可
在一处编辑,其他地方自动更新。点击右边的数字可以看到原始的内容。这样既可以发挥 Logseq 快速记录的特性,又能让相关内容很好地聚合。
copy ref 和 copy embeds 都可以同步显示内容。区别是,前者只能展示一级内容,且点击后会跳转到 Source Block,后者可以展示多个层级的内容,且可以就地编辑。
在页面内将相关 Block 按不同维度聚合
因为 Block 与 Page 之间是通过属性间接关联在一起的,所以这些 Block 不会自动出现在该 Page 下,需要通过 Advanced Query 将它们检索出来,相关的 Code 上面已经有了,这里看下展示效果:
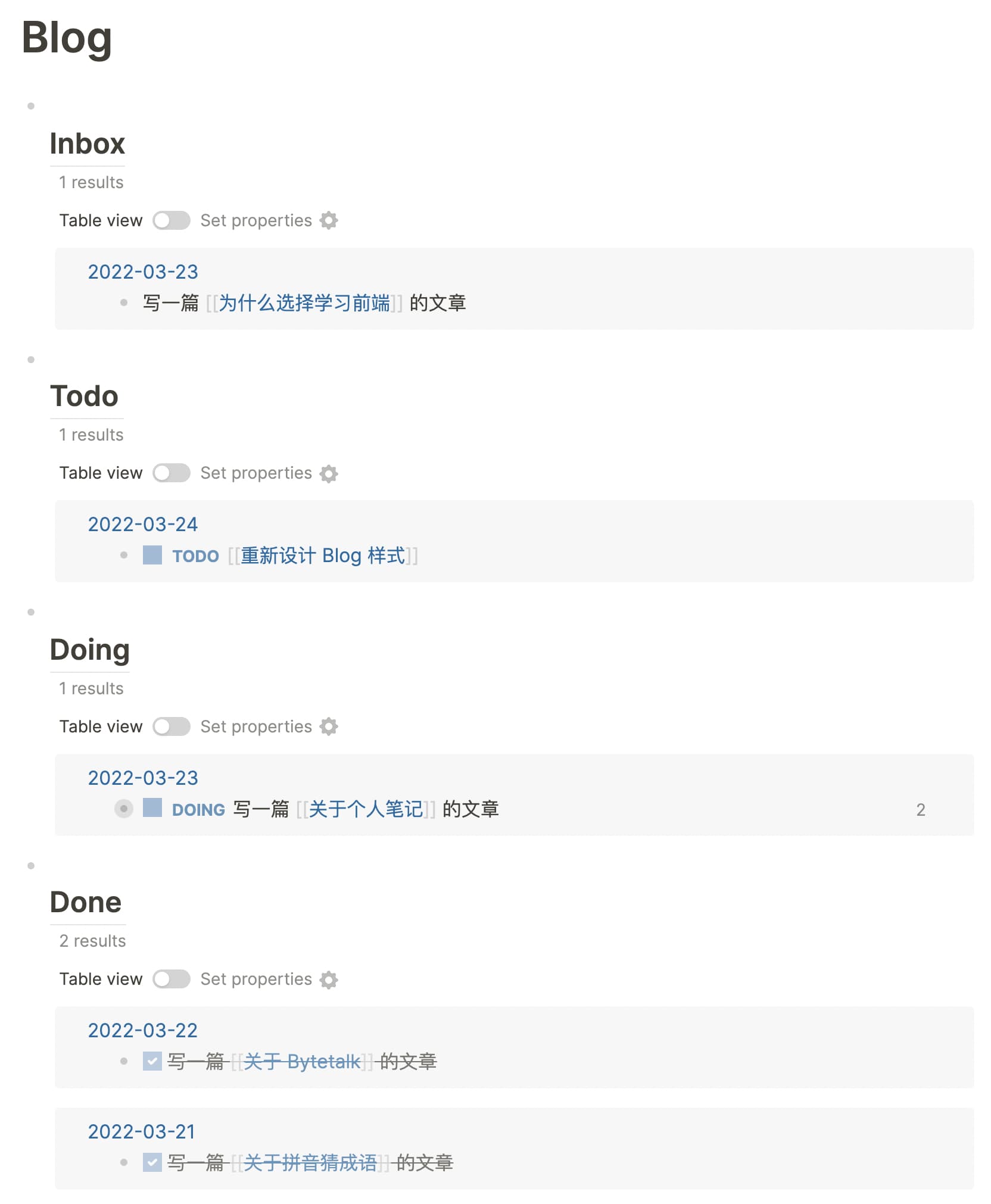
划分的维度很简单:
- Inbox: 没有 Todo 标记的(
(not [?b :block/marker ?m])),表示将来某一天可以做 - Todo: 标记为
TODO的 Block - Doing: 标记为
DOING的 Block - Done: 标记为
DONE的 Block
这里需要在设置里将 “DOING 耗时统计” 这一项关掉,不然只要在 TODO 和 DOING 状态间切换就会进行耗时计算,这跟我们的使用姿势不符。
假如 Todo 列表空了,就从 Inbox 中找几个,状态切换为 TODO ,就会自动出现在 Todo 这个 Group 下。
假如 Doing 的做完了,从 Todo 中找几个,状态切换为 DOING (点击 TODO 按钮即可),就会自动出现在 Doing 这个 Group 下。
一并管理 Todo
用 Logseq 管理 Todo 不是一个顺便的行为,而是合适的行为。对于 Todo 来说,我觉得 Context 是很重要的,而 Logseq 可以为 Todo 提供足够多的 Context,同时可以将 Todo 和其他 Block 联系起来。
场景模拟
今天的待办事项有哪些
先从昨天的 Todo 中找哪些今天可以继续做的,通过 copy ref 的方式,放到今天的 Todo 列表中。
用 copy ref 可以保持一致性,只要修改一处,其他地方都会同时更新。
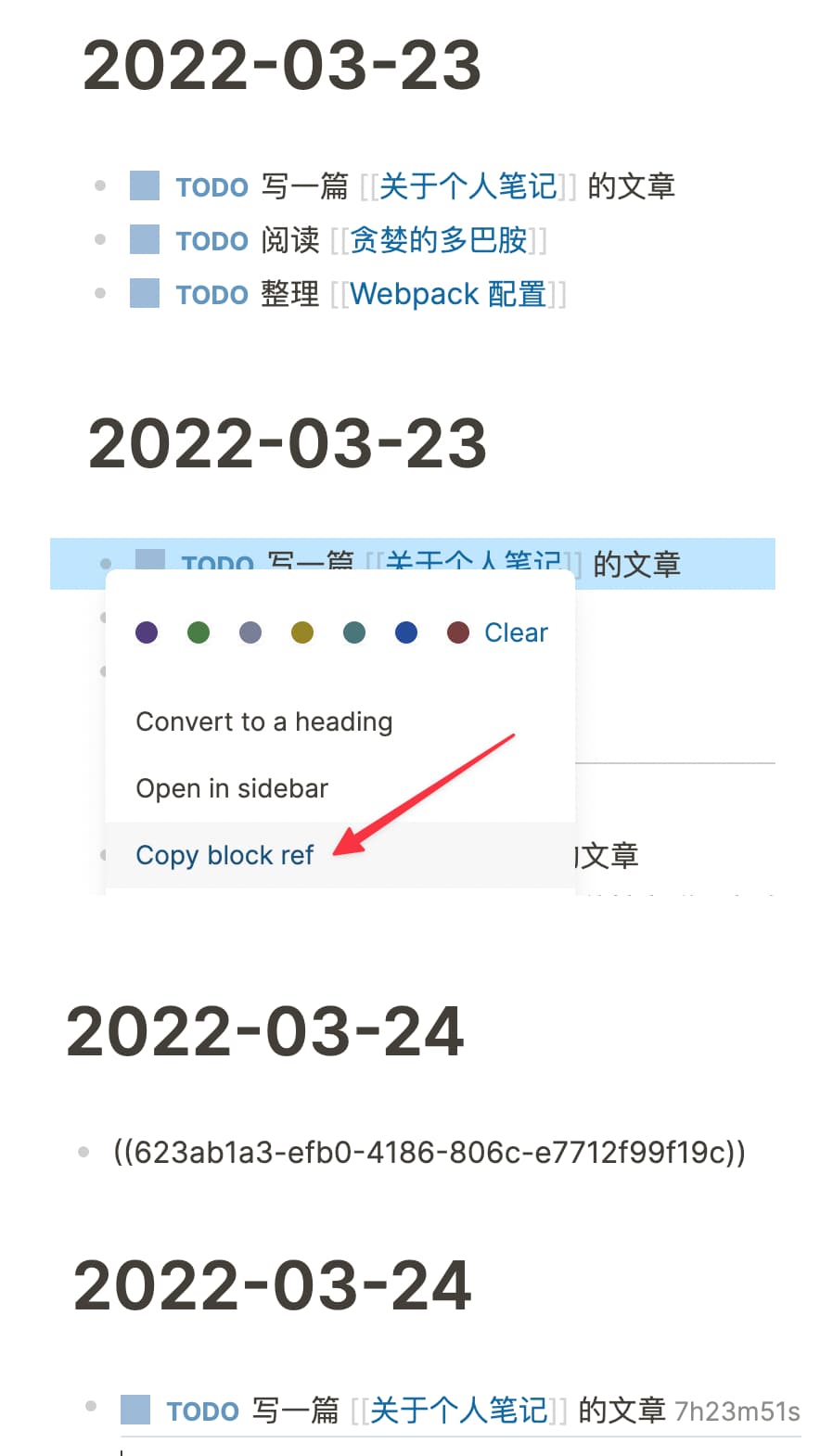
点击进去后可以看到相关的引用
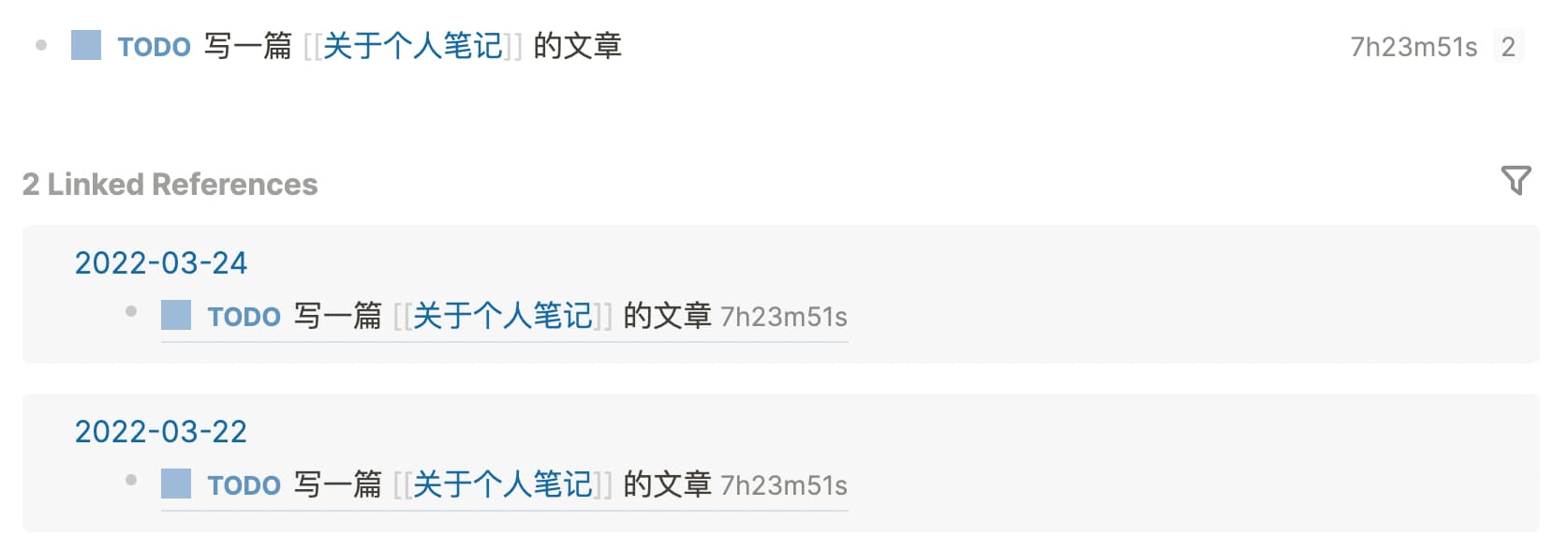
注意到 Block 后面的数字,这是 Logseq 的一个 Feature:点击 「TODO」后会切换到「DOING」,同时开始计时,当再切换到「TODO」或「DONE」时,就能看到经过了多少时间。可以在 Settings 里关闭该功能。
如果这几个 Todo 做完了,可以从其他标为 Favorite 页面的待办里挑几个出来。「挑」的过程就是将 Block 的 /TODO 切换为 /DOING,然后 copy ref 到今天的 Todo 列表里。
我的一些 Favorite 页面,方便回顾
- Ideas // 随时冒出来的一些想法
- Thoughts// 自己的一些思考
- Pearls // 网上看到的一些不错的内容
- Tiny // 记录生活中的一些小细节
- Articles
- Books
- Frontend
- Programming
这个视频的作者用了另一种维度来作为 Daily Entry 的模版
- Create
- Consume
- Connect
- Celebrate
- Coordinate
- Consolidate
做读书笔记
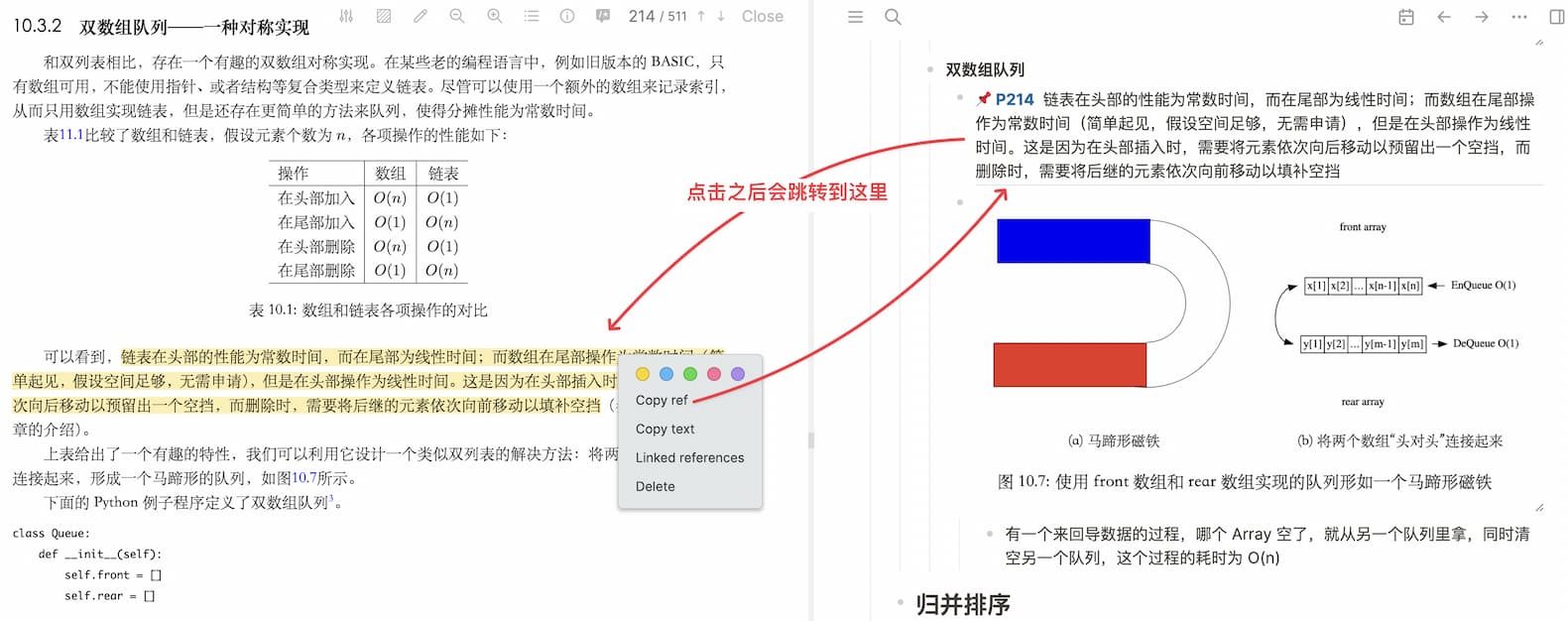
这是 Logseq 的又一个亮点,通过命令 /Upload an asset 上传 PDF 文件后(其实就是将文件拷贝到 Logseq 在本地的目录),点击该文件可以左右分栏,左边是 PDF 电子书,右边是笔记区。阅读过程中,如果有想记录的内容,可以先在 PDF 中高亮,然后右键选择 copy ref,在 Block 中粘贴,就能引用到这些文字了。相比传统的复制粘贴,copy ref 的内容点击后,可以回到 PDF,进而查看更多的上下文。也可以方便地加入自己的 Comment
临时出现的待办事项
可以新建一个 Inbox 页面,然后把事项放到当天的 Journal 页,打上 Inbox 标签。如
• 帮忙调研某个产品 #Inbox
• 用户反馈了个 Bug #Inbox
然后就可以在工作间隙,Review 这些 Inbox 项,看是否应该在今天处理,是否要加上特定的属性(方便归类到特定的页面)。
回顾
回顾是一个很重要的过程,对于学到的内容可以加深印象,了解进行中的事情处于什么状态,帮助制定下一阶段的计划。对于每一个需要回顾的页面,可以都加入到侧栏的 Favorites,同时结合 Advanced Query 把 Block 按 Todo / Doing / Done 区分开来(像 Ideas / Thoughts 这样的页面就不需要了)。
如果担心遗漏,可以按日期来 Review
小技巧
- 输入
/会出现自动提示,比如设置为 TODO,上传附件等,其中/Today和/Current time很方便,前者可以自动添加当前日期,如[[2022-03-24]],这样就会以 Back Link 的形式出现在2022-03-24Journal 页。后者会输出当前时间(精确到分钟),可以用来记录时间消耗。/Draw甚至可以嵌入一个画板。 - 使用
可以把content隐藏起来,点击后展开,可以用来记忆单词。 - 将常用的结构设置为 Template(比如每天的例行事项,右键点击左边的小圆点可以看到这个选项),在需要的地方选择该模版即可自动填充模版内容。
- 在设置里开启「Developer mode」后,可以安装 Plugins 和 Themes
- 按住
Shift点击 Page 链接,可以在 Sidebar 打开,方便同时浏览 - 编辑代码或者 Query,可以点击上面的空白区域
小结
以上就是我目前的 Logseq 使用习惯。因为 Logseq 灵活又强大,大家的使用姿势都不太一样,以下这几个链接也可以一并参考:
- 我的人生管理系统
- OKR + GTD + Note => Logseq
- How I Use Logseq to Take Notes and Organize My Life
- 我是如何使用 Logseq 的 (via Randy)
- How I Orgnise My Life 作者用的 Roam Research,可以参考下使用理念
- Roam Research 作者是如何使用 Roam Research 的
来源分类:B chinese bloger
文章日期:March 25, 2022 at 03:30PM
收藏日期:March 25, 2022 at 03:30PM