本文转自: http://xueqiu.com/5672579962/363223331
仅做个人收藏,版权归原作者所有
<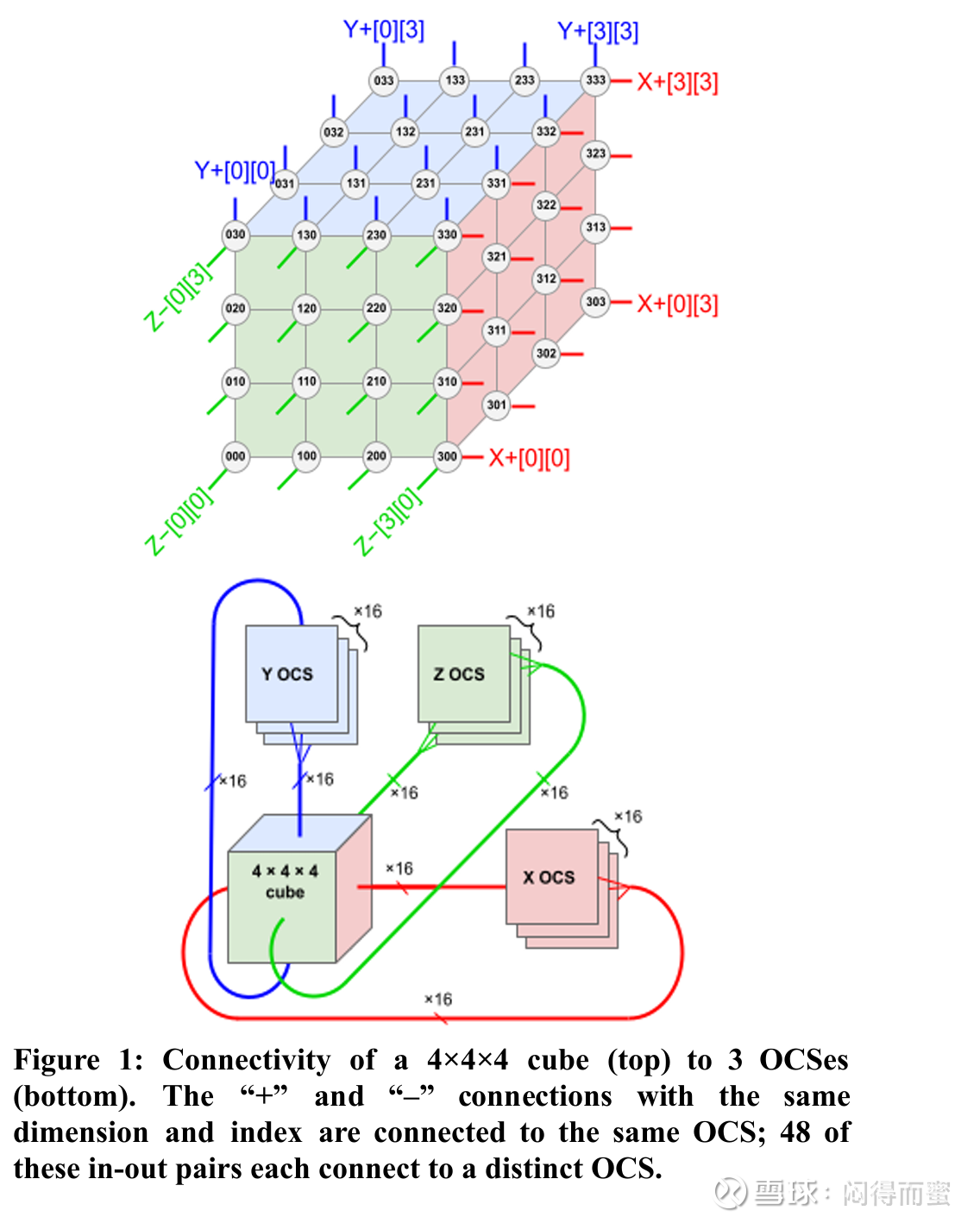
TPU v4 是首个部署可重构 OCS 的超级计算机,OCS 能够动态重构其互连拓扑以提高规模、可用性、利用率、模块化、部署、安全性、功耗和性能。在 Ironwood(博通代工) 集群中,48 个 OCS 交换机连接 9,216 个 TPU 芯片,创建了一个低延迟、高带宽的动态光子网络。
CLOS full mesh 架构
英伟达采用两级 CLOS(Fat-Tree)拓扑。第一级:在单个节点内部,多颗 NVSwitch 芯片构建了一个单级的、逻辑上完全无阻塞的全互联网络(Full Mesh),将域内所有 GPU 全互联起来。第二级:第一级的 NVSwitch 再通过第二级的 NVSwitch 进行互联,形成一个 更大的 Scale-Up 通信域。
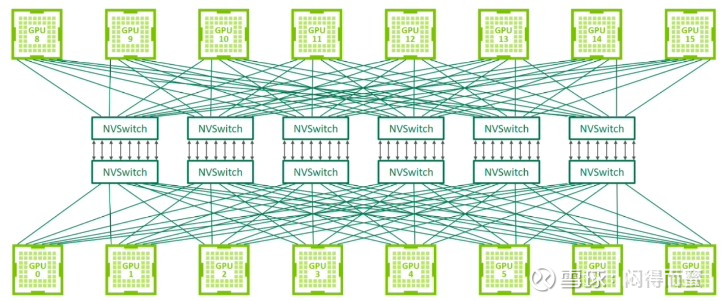
这种架构的优势在于其高度的模块化和可扩展性。CLOS 架构最简洁的部署方式是 Spine-Leaf 的两层网络架构,在经典 CLOS 架构下,所有交换机端口数量相同(n 个),两层 CLOS 下最大接入的服务器网口数量为 n×n/2,以 n=64 为例,接入的服务器网口数量可达 2048 个。
大模型演进与 MoE 适配性:CLOS 的天然优势
随着大语言模型参数规模突破万亿级别,混合专家模型(MoE,Mixture of Experts)成为降低训练成本和提升模型能力的关键技术。MoE 架构的核心创新在于将传统的密集前馈网络层替换为稀疏激活的专家网络集合,每个输入 token 被动态路由到少数几个专家进行处理。
MoE 模型的通信模式与传统模型存在根本性差异。在 MoE 架构中,每个输入 token 被路由到选定的专家,然后通过全对全(all-to-all)GPU 通信交换结果。这种独特的架构允许引入一种新的模型并行维度,称为专家并行(EP),其中不同的专家网络分布到不同的 GPU 上,这导致在模型层之间产生密集的 All-to-All 通信模式。
CLOS 架构对 MoE 的天然适配性
CLOS full mesh 架构全连接特性完美匹配 MoE 的通信模式。在 MoE 模型中,每个 token 需要根据路由结果从对应的专家 GPU 获取计算结果,这种 All-to-All 通信对网络的全局带宽和拓扑结构提出了更高的要求。CLOS 架构的全互联特性确保了任意两个 GPU 之间都有直接的高速连接,无需经过复杂的路由路径。
Torus 架构在 MoE 场景的局限性
MoE 的稀疏激活特性,在前向/反向传播中仅激活部分专家(如 Top-k,k=1~2),导致非规则、动态、稀疏的通信需求。
Torus 架构因其规则性、低成本和良好局部性,在传统 HPC 中表现优异,但在 MoE 这类动态、稀疏、全局通信密集的 AI 工作负载下,其通信效率、扩展性和负载均衡能力明显不足(最多长达20跳)。
在Torus 中,任意两点间最大跳数为 O(N)(N 为节点数),且中间链路共享度高,容易在热点路径上形成拥塞瓶颈,降低整体吞吐。相比CLOS Full-mesh,Torus 完成 All-to-All 需要更多跳数和同步轮次,通信时间随规模平方级增长。
实测数据印证 CLOS 的优势
学术研究为我们提供了有力的证据。TA-MoE(拓扑感知的大规模 MoE 训练方法)的研究表明,在不同的网络拓扑和模型配置下,通过自适应调整通信量以适应底层网络拓扑,可以实现显著的性能提升。实验结果显示,TA-MoE 相比 DeepSpeed-MoE 实现 1.01x-1.61x 加速,相比 FastMoE 实现 1.01x-4.77x 加速。
更重要的是,在跨交换机通信的 Cluster 上获得了更多改进,某些情况下可达 4.77x。这一结果充分说明了网络拓扑对 MoE 模型性能的决定性影响,也间接印证了 CLOS 架构在处理复杂通信模式时的优势。
技术演进路径:CLOS 的工艺红利与 Torus 的扩展困境
CLOS 架构的摩尔定律红利
摩尔定律为 CLOS 架构提供了持续演进的强大动力。摩尔定律预测集成电路上可容纳的元器件数目约每隔 18-24 个月便会增加一倍,性能也将提升一倍。这一规律不仅适用于处理器,同样适用于网络交换芯片,为 CLOS 架构的持续改进提供了理论基础。博通 Tomahawk 系列交换芯片的演进历程完美诠释了这一规律:
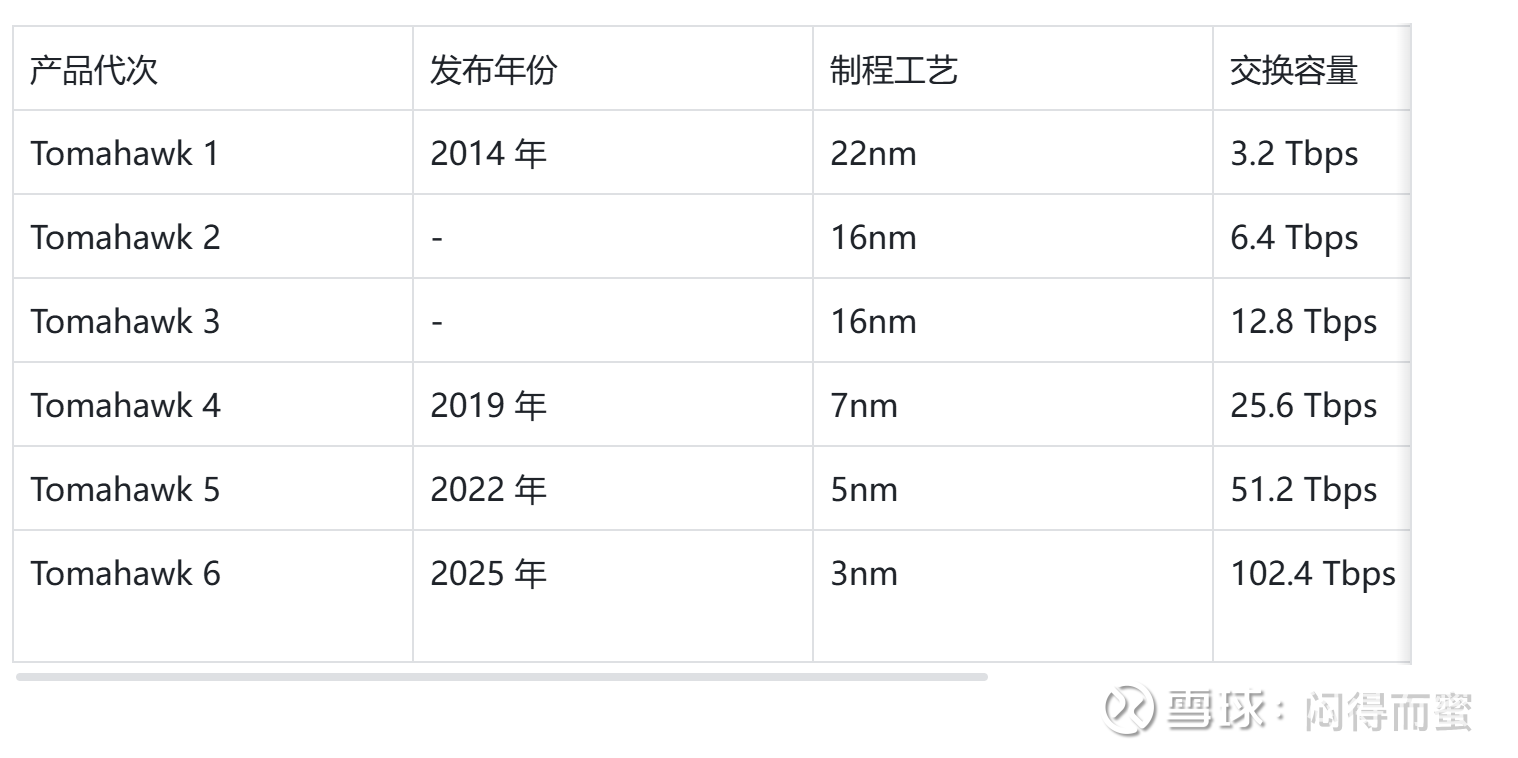
制程工艺的持续进步直接转化为性能提升。Tomahawk 4 采用 7nm 工艺,容量翻倍至 25.6Tbps,能效比提升 50%;Tomahawk 5 采用 5nm 工艺,功耗降低 30%;最新的 Tomahawk 6 采用 3nm 工艺,单芯片交换容量达到 102.4Tbps,较现有以太网交换机带宽翻倍,并支持超大规模 GPU 集群的互联需求,单层芯片即可驱动多达 10 万张 GPU 协同工作。
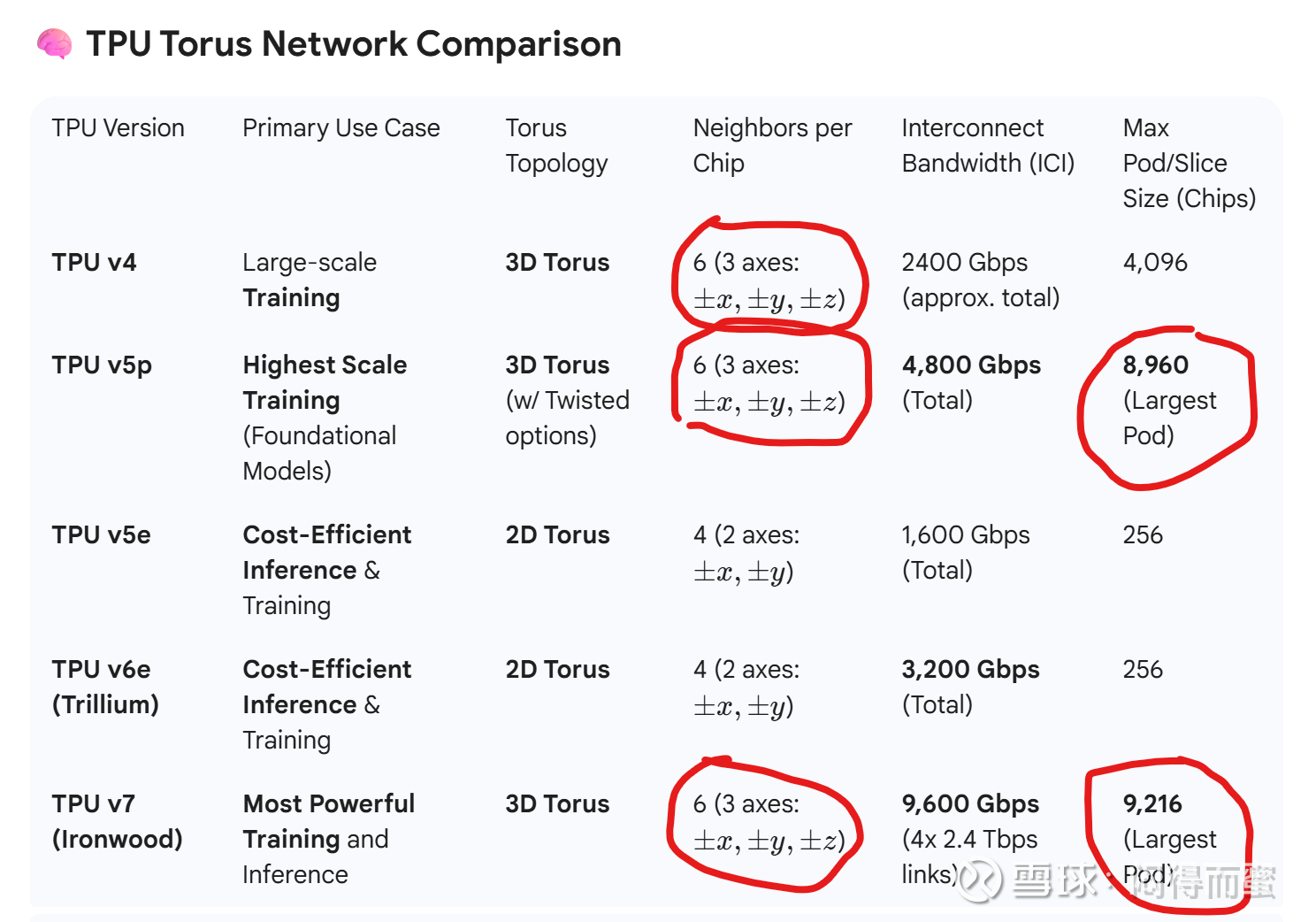
相反,Torus架构很难演进,过去三年,规模基本都固定在三个维度六面,最大芯片数量在8K左右。如果继续扩充,比如四维结构,难度是四次方的关系。
软件栈复杂度:CLOS 的简单性 vs TPU 的拓扑感知挑战
CLOS 架构的软件优势:标准化与自动化
CLOS 架构在软件设计上的最大优势在于其高度的标准化和自动化能力。这种优势源于 CLOS 架构的内在特性:所有 spine 交换机执行相同的角色,所有 leaf 交换机也执行相同的角色,这种均匀性使其非常适合自动化,随着网络规模的扩大,运营复杂性会降低。
标准化带来的互操作性。在数据中心 BGP 配置中,CLOS 网络的丰富连接矩阵可以通过生成树协议(STP)分解为无环树结构,拓扑简化为类似 spine-leaf 的结构,每个 spine 有 32 个链路连接到每个 leaf94。这种标准化的结构使得不同厂商的设备能够无缝集成,降低了系统的复杂性。
TPU 软件栈的拓扑感知复杂性
与 CLOS 的简单性形成鲜明对比的是,TPU 的 Torus 架构在软件层面带来了巨大的复杂性挑战。这种复杂性不仅体现在编译器层面,更贯穿整个软件栈。
编译器层面的拓扑感知需求。谷歌专门创建了编译器和软件栈,将来自 TensorFlow 图的 API 调用转化成 TPU 指令。TPU-MLIR 作为 AI 编译器,需要把不同框架下搭建的模型转换为统一形式的中间表达 IR,然后通过 IR 转换成可以在特定芯片平台上运行的二进制模型。这种转换过程必须充分考虑 Torus 拓扑的特性,包括路由路径、带宽限制和潜在的死锁风险。
拓扑感知优化的挑战。为了充分利用 TPU 的性能,开发者必须在代码中显式考虑 Torus 拓扑结构。这包括数据布局优化、通信模式设计和负载均衡策略等多个方面。例如,在分布式训练中,必须确保数据在 Torus 网络中的传输路径经过精心设计,以避免热点和死锁。
学习成本的对比
从开发和学习成本角度分析,两种架构的差异更加明显:
CLOS 架构的低门槛优势。CLOS 架构的软件界面简单,网络拓扑对上层应用透明。开发者不需要了解底层网络的具体拓扑结构,只需要关注逻辑上的全连接特性。这种透明性大大降低了开发难度,使得现有的 AI 框架可以轻松适配 CLOS 架构的集群。
TPU 架构的高学习成本。相比之下,TPU 的 Torus 架构要求开发者深入了解网络拓扑。在实际编程中,虽然开发者通常不需要直接操作脉动阵列,而是通过高级框架如 JAX 或 PyTorch 的 XLA 后端来自动优化计算图,但这种 “自动优化” 往往需要大量的人工调优才能达到理想性能。
生态系统的成熟度差异。英伟达的 CUDA 生态系统经过多年发展,已经形成了完善的工具链和丰富的文档资源。开发者可以轻松找到各种性能优化的最佳实践和问题解决方案。而 TPU 的生态系统相对年轻,虽然 Google 提供了 JAX 等专门优化的框架,但整体的工具链成熟度和社区支持度仍有差距。
当然,Torus也有优势,最大的特点就是低成本、低功耗。同样的规模和性能,Torus的互联Capex大约只有CLOS full mesh的50%。但是,随着英伟达积极引入Cabless正交背板、CPO等创新技术,CLOS的网络成本也会显著下降。
综上,谷歌携TPU+OCS给英伟达带来挑战,但因为最基础的互联架构选择不同,决定了对英伟达的冲击有限。不管谁赢,是不是都要找台积电投片呢?
$谷歌A(GOOGL)$ $英伟达(NVDA)$ $台积电(TSM)$
本话题在雪球有146条讨论,点击查看。
雪球是一个投资者的社交网络,聪明的投资者都在这里。
点击下载雪球手机客户端 http://xueqiu.com/xz]]>