本文转自: https://saltyleo.com/result/8qI4ENZsrkVOAB0JKl7u
仅做个人收藏,版权归原作者所有
前言
自从国内图书界最大的【豆瓣读书】关闭公共 API 后,很多图书元数据削挂插件都失去了作用,所以我自己使用手上现有的资源制作了一个新的 API 服务,地址:https://book-db-v1.saltyleo.com/
本文的主题是分享一下我做出来的新玩意,欢迎各位大佬调试~
使用方法
端点URL: https://book-db-v1.saltyleo.com
请求方法: GET
响应格式: JSON
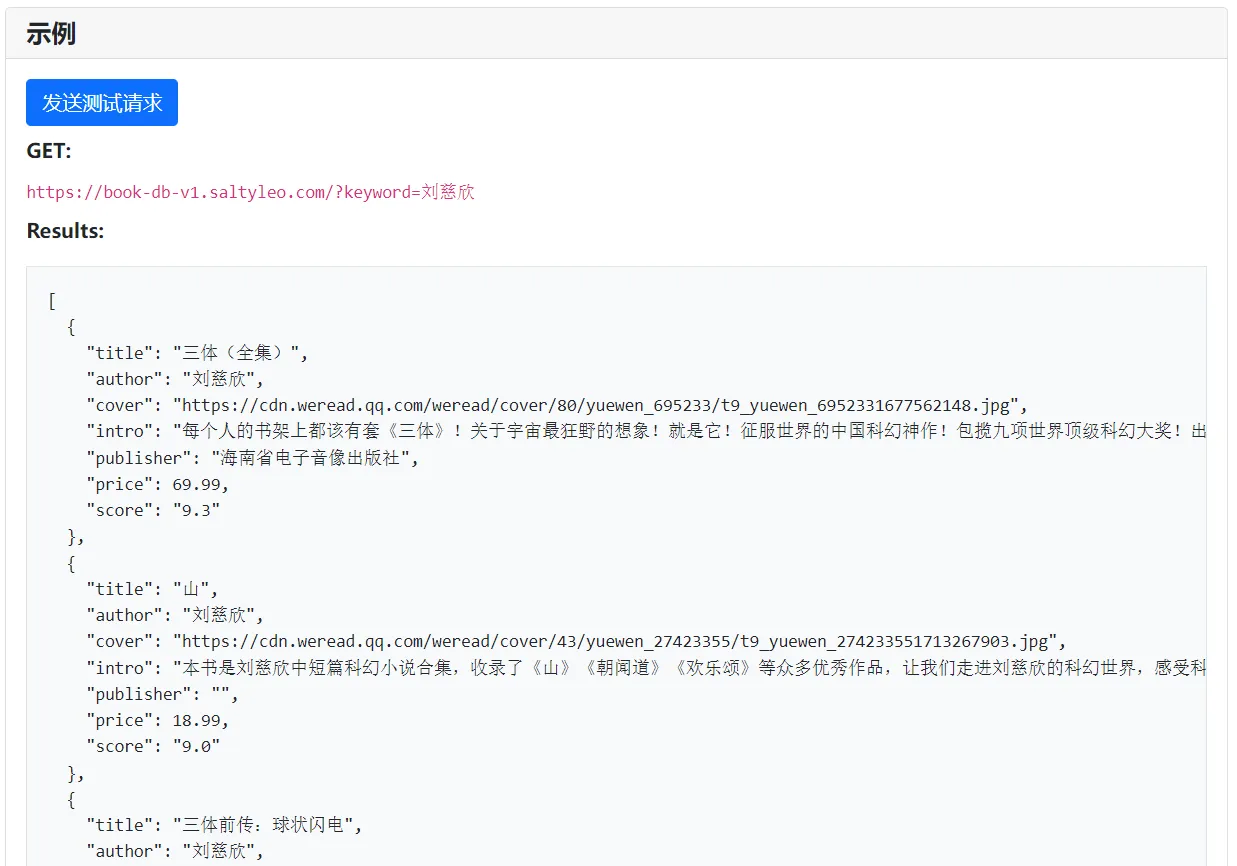
你直接点击这个链接,:https://book-db-v1.saltyleo.com/?keyword=刘慈欣 ,就可以得到与【刘慈欣】有关的前 10 本图书信息,对于开发者,直接解析 JSON 即可使用。
如果是非开发者,只想在网络上找到心仪的电子书,那直接去我的书架找更快些:SaltyLeo的书架
我做了什么?
我之前不是做了一个电子书查询网站嘛,在收集数据的过程中我发现,很多电子书网站的书籍信息都很少,往往就一个名字。手动去搜索引擎找也不是不行,就很低效,所以做出了这个 API 方便我了解书籍信息。
想着既然都做出来了,独乐乐不如众乐乐,索性就将其公开了,之所以提供 API 方式调用,也是为了方便其他人如果也想做自建书站,或者开发新的削刮插件的话,直接调取 API 获取数据即可,省去了很多收集数据,处理数据的时间,直接解析 JSON 即可放在项目上使用。
这只是第一版的 API,所以数据内容偏少。会逐渐补充。而且我对于大数据领域还是蛮感兴趣的,这个API 会稳定迭代,也会长期运营。
后端是基于 CloudFlare Worker 部署,费用几乎为零,当然为了避免高额的账单,我通过 CloudFlare 设置了最大 QPS,限制为 10,也就是说,每秒最多访问 10 次,这对于一般数量的电子书削刮来说已经够用了,1 分钟可以处理 600 本书呢,小规模数据稍等片刻就能处理完毕。如果你是有几十万本,或几百万本的,你可以使用 IP 池,或其他多线程爬虫技术。反正要是快被刷爆了,我会进一步限速的😏
后记
有了 AI 的加持,以前要深入了解学习后才能实现的事,现在变得很轻而易举了。学习的速度呈指数增加,像是 JS 我到现在对它还是一知半解,但不妨碍我能够让 AI 帮我写我所需要的功能,我觉得低代码和无代码还是不可靠的,AI 生成的代码片段总是有各种而样的BUG,需要手动修复。
最后,我只做了一些微小的工作,将散落在互联网上的数据略微做了整理和归纳,不值一提。