本文转自: https://www.kingname.info/2024/02/18/lmstudio/
仅做个人收藏,版权归原作者所有
经过一年多的发展,各种开源大模型现在已经相当不错了。国产的Qwen 1.5的生成效果已经能满足一些日常使用。
有一些同学可能之前一直在用网页版的ChatGPT、Kimi Chat、文心一言或者通义千问,那么你可能会遇到如下一些问题:
- 网络问题。例如ChatGPT需要特殊的网络才能访问。
- 审查问题。国产大模型会大量屏蔽关键字,有一些你觉得完全没有任何问题的回答,它会告诉你不符合法律规范,不能回答。
- 不能自定义模型,网页版的这些大模型,你没有办法做微调,难以自定义内容。当你花了大量时间设计了一个高级Prompt,把模型洗脑成了猫娘,结果第二天它又不能用了。
- 隐私泄漏问题,担心大模型的开发商把你问的问题和上传的信息挪作他用。
当你被这些问题困扰,那么你可以考虑离线运行开源大模型。完全不需要网络,因此不存在隐私泄漏的问题。你可以随意对模型进行微调,想弄成猫娘还是伪娘都随你的想法。没有任何审查,想怎么问怎么答都可以调整。
在2023年早期,要离线运行开源大模型是一件非常困难的事情。首先是显卡,4090显卡非常昂贵。其次是环境,搭建起来非常麻烦,各种报错会浪费你大量的时间。
但这些问题现在都不是问题了。使用LM Studio,你只需要3分钟就能在自己电脑上运行开源大模型。并且能自动开启兼容openai库的API.要运行大模型的门槛也大大降低,只需要满足:
- 苹果芯片(M1/M2/M3)的Mac,操作系统大于等于13.6
- Windows/Linux系统,只要处理器支持AVX2。最近3年的电脑基本上都支持。
- 16GB以上的内存最好,但8GB也能跑
- Windows/Linux使用的显卡不是太差即可。
要使用LM Studio非常简单,首先在官网下载安装包进行安装。安装完成以后如下图所示:
接下来,需要下载开源大模型。这是整个步骤里面,唯一需要联网的地方。由于它会从Huggingface上面下载大模型,但这个网站已经被墙了,因此你需要自己想办法绕过。这里我以Qwen 1.5-7B为例。虽然这个模型只有7B,但是经过我测试,它已经相当不错了。
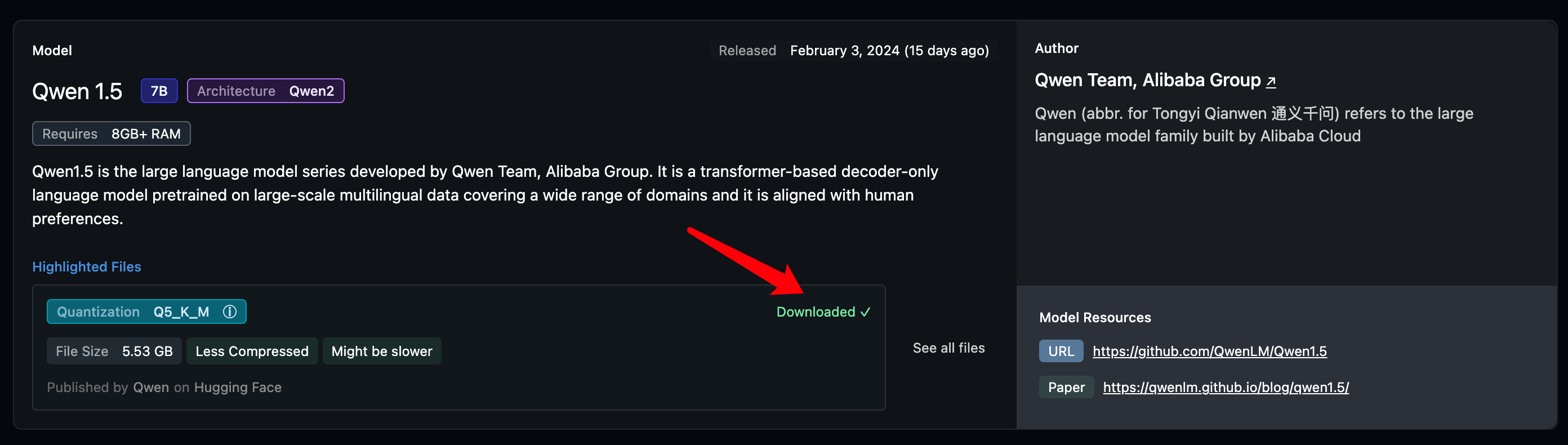
当你第一次运行LM Studio时,上图箭头指向的地方应该是一个绿色的Download按钮,点击就可以下载。5.53GB,很快就下载完成了。如果你想下载其他的模型,可以直接在第一张图的搜索框进行搜索并选择合适的大小下载。
下载完成以后,我们进入LM Studio的聊天页面,如下图所示。
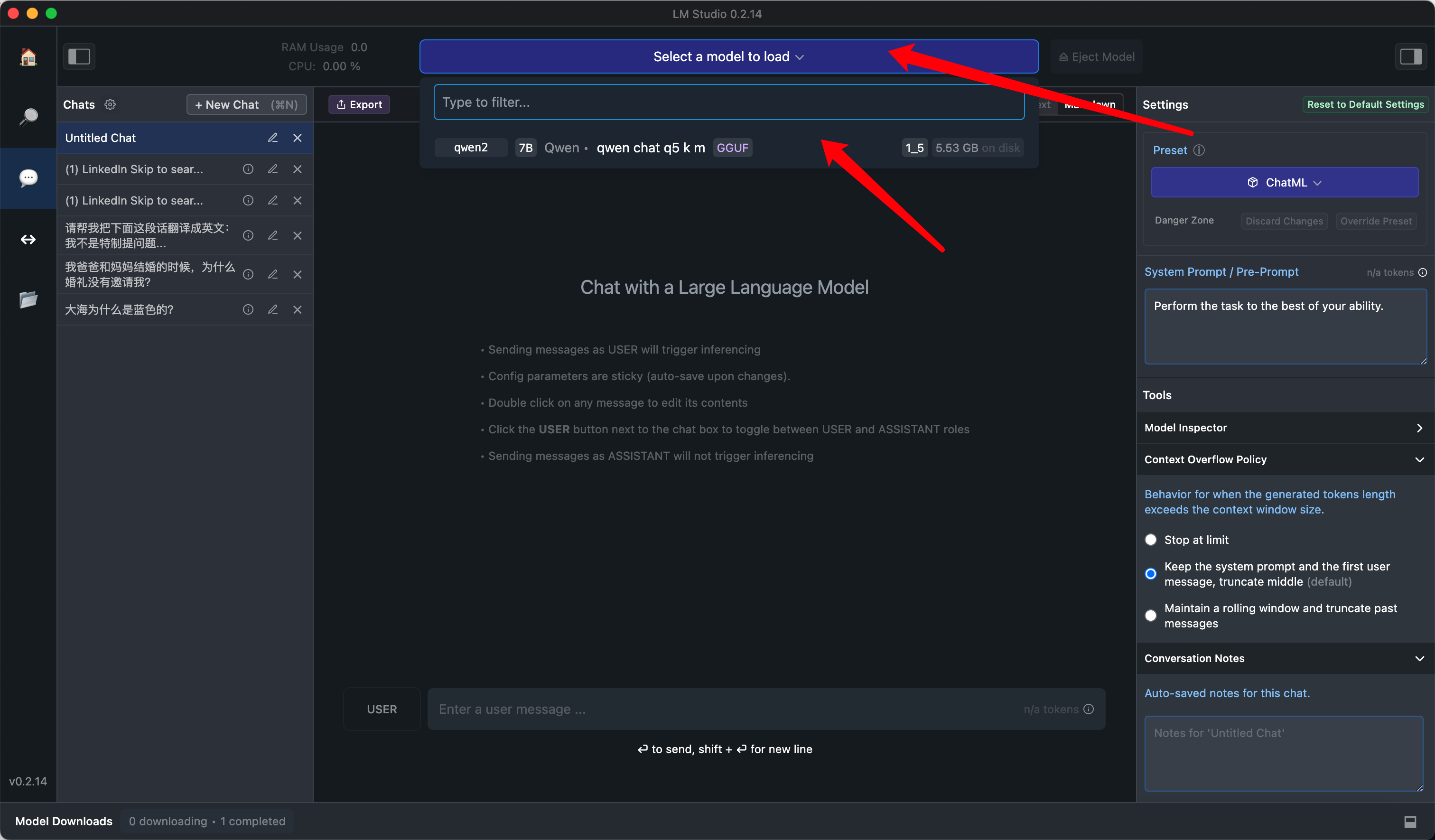
在顶部选择你刚刚下载的大模型,就可以开始对话了。下面这个视频,是我使用macbook Pro M1的运行效果,可以看到速度还是很不错的。
在右侧的设置中,还可以定制System Prompt,调整最大允许的Token长度,或者勾选mac是否使用GPU加速等等。
LM Studio最强大的功能,是可以直接基于你选定的大模型生成一个API接口,这样一来你就可以写Python代码来调用了。
在最左侧点击左右箭头的按钮,打开Local Server功能,如下图所示:
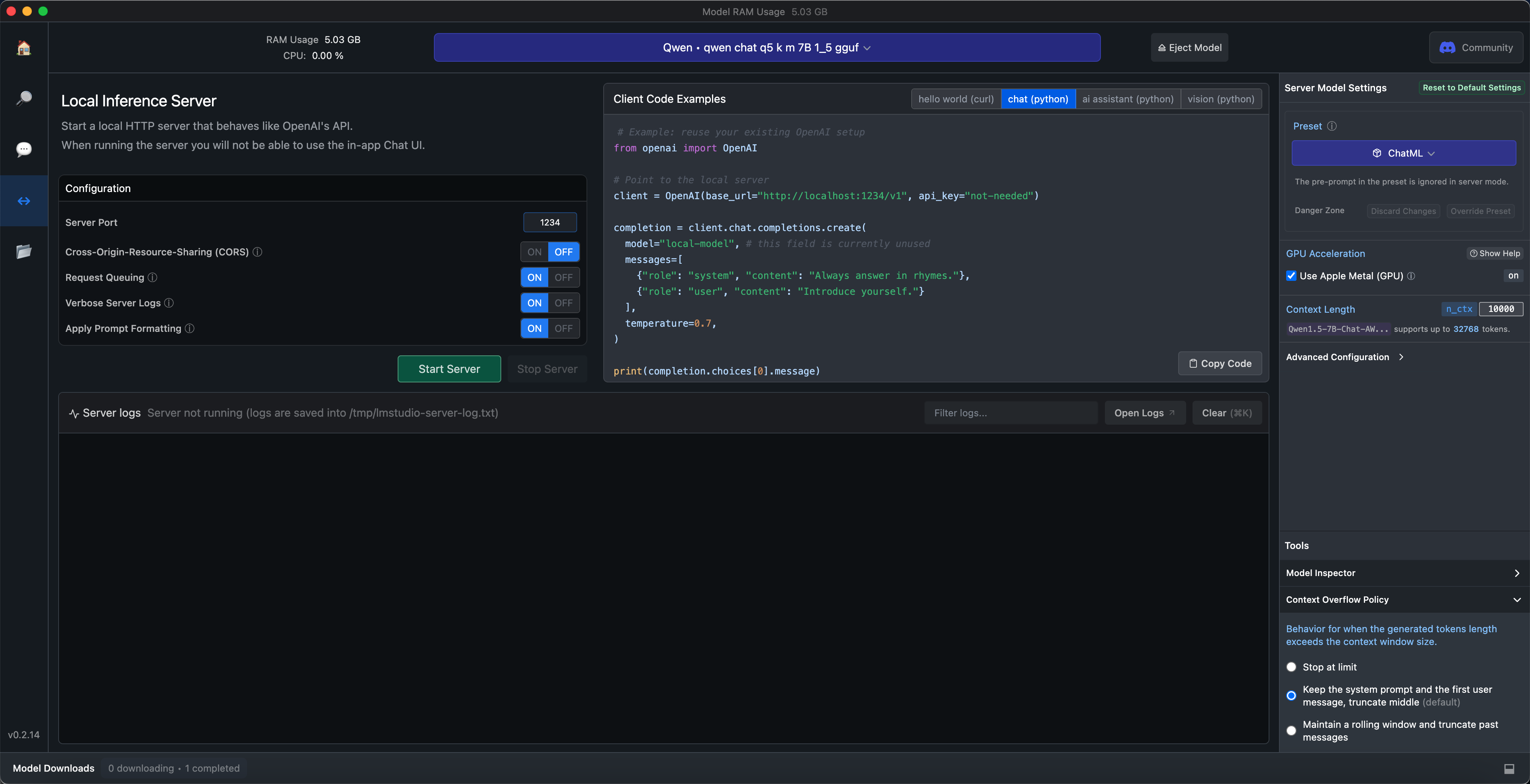
你基本上不需要做任何修改,直接点击Start Server按钮,就可以启动接口。然后从它给出的示例代码中复制Python代码。
我们以《一日一技:自动提取任意信息的通用爬虫》这篇文章中讲到的使用GPT从Linkedin源代码中提取招聘信息的例子来演示。但把GPT 4换成了Qwen 1.5-7B.代码如下:
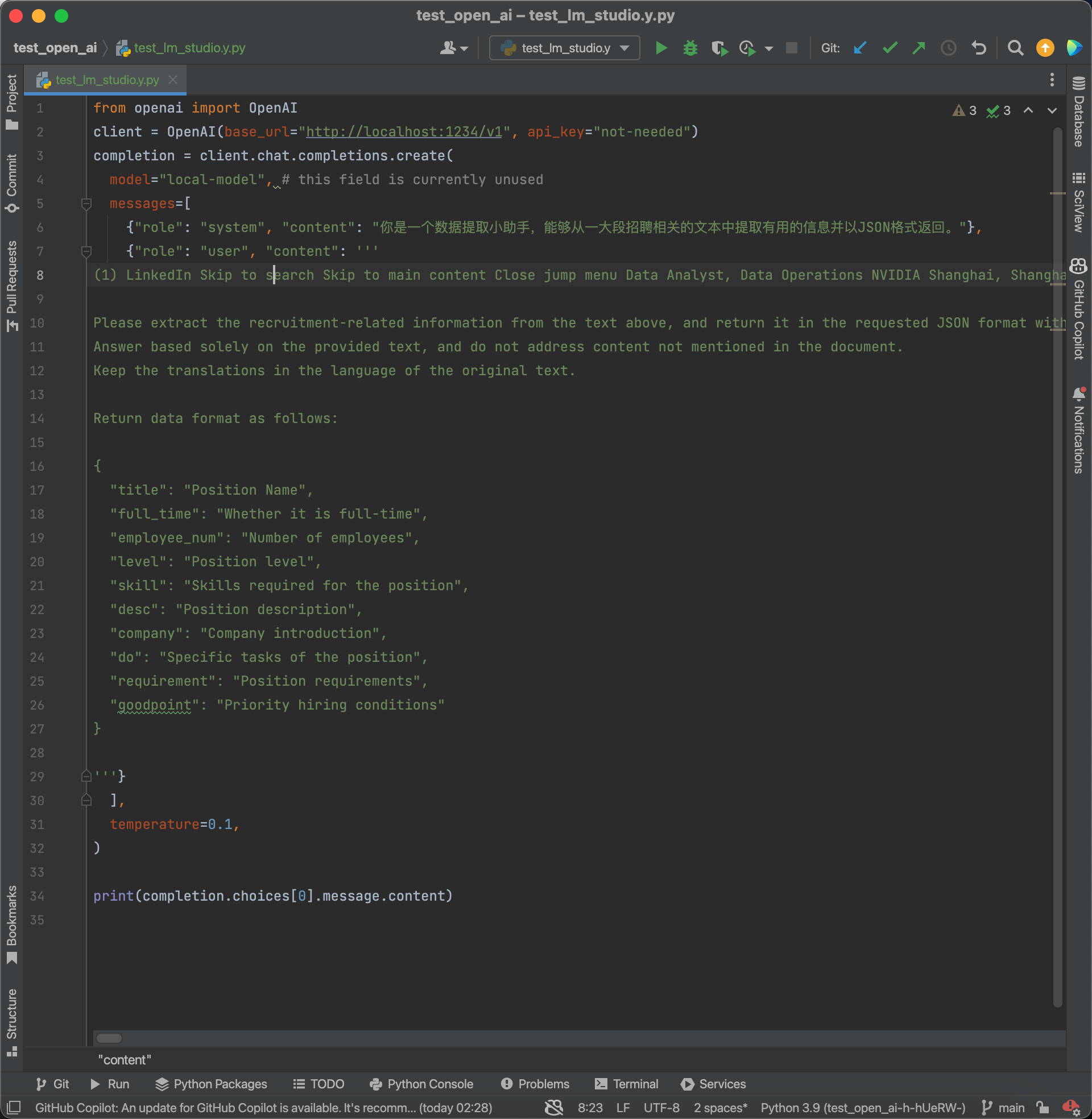
提取出来的结果如下:
1 |
{ |
这个提取结果跟GPT 4 Turbo的提取结果比起来,几乎是一样的。虽然有一些小小的瑕疵(company字段被擅自增加了嵌套字段),但这只是一个小小的7B模型,并且运行在一台小小的笔记本上面而已。而且完全免费。这样的瑕疵是完全可以接受的,并且可以通过一些工程手段来修复。如果你的显卡更高级,你可以试一试使用Qwen 1.5-14B甚至Qwen 1.5-72B,效果肯定会更好。
需要注意的是,Qwen 1.5-7B毕竟是国产大模型,针对中文做了大量的优化。因此如果你希望结果保留英文,就尽量使用英文的Prompt。否则它会擅自把提取结果翻译成中文。如果你需要处理的内容包含大量英文,你可以考虑使用LLama的最新大模型,而不是国产大模型。
总结一下,使用LM Studio,你可以立刻拥有一个完全属于你自己的大模型。运行在你自己的电脑上,没有隐私问题,没有网络问题,可以自由定制,而且完全免费。还能一键开启API,兼容openai库,从而自己写代码开发更多基于大模型的功能。